
One design pattern that is a particularly great fit for AI-first dev is managed effects (AKA capabilities).
The basic idea with managed effects is that we mechanically restrict what a piece of code can do by only giving it access to specific capabilities.
This creates a sort-of sandbox around that piece of code, which helps us make some issues that are specific to agentic dev far more manageable.
We’ll use a small example that uses this design pattern to illustrate what kind of benefits we can get from it.
Then we’ll talk about why it makes more sense to use these patterns much more often in the age of AI.
Our example: HTTP API endpoint data access
An important aspect of an API endpoint is what data it can read and write.
If we could know this at a glance, it’d be useful for reasoning about both logic and security.
Maybe we can think of a “UI for looking at important things in the software”, and it would contain something like this:
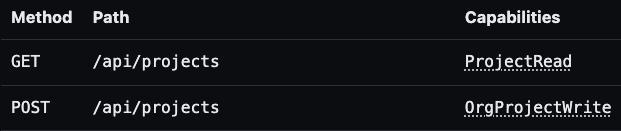
Note - these UX examples are not from an existing tool. Some of them are screenshots from a POC project that I built to flesh out these ideas (code linked below), and some are just UI mocks.
When looking at the diff while we’re working on a task or reviewing it, we can hope to have this:
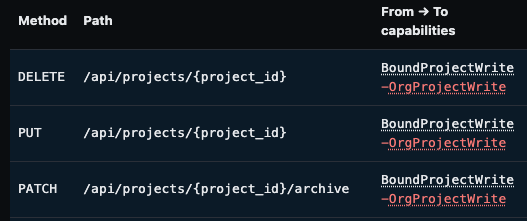
If we’d like to go further, we might also imagine a UX for reviewing changes which is “stronger”.
Changes to scope of data access are dangerous, so maybe we’ll want to go with a “dangerous change” UX for that.
Maybe a required-form:
Warning · capability surface change This PR adds capabilities to an HTTP endpoint.
Acknowledge the changes below before merging PR #482.
main
OrgTicketWriteCapability lets the route create, update, move, assign, and delete
tickets in the caller's org. Each verb is role-gated; super-admins bypass the org check.
Looks like a wiring mistake, not an intentional widening: a GET route shouldn't
need write verbs, and a projects route shouldn't need ticket writes.
Recommend bouncing back to the author.
We can also hope to “give these benefits to the agent as it codes”:
- Smaller context - when considering an API endpoint, it would be good if the agent fetch “just the right part of the DB access layer” for that endpoint.
- Make it easier to avoid important categories of bugs - in this case, help the agent write code so that it’s guaranteed that it would stay within the guardrails and not access forbidden data.
Why can’t we just have this with any arbitrary design?
For simple code, it might be possible to have a static analysis tool figure all this out.
For large, complex code, it becomes difficult to know for sure that a rare input + rare state won’t lead us down
an unexpected code path.
This is where managing capabilities comes in:
Design pattern: Limit API endpoint DB access
The typical design for an API handler is that it has full access to the db, and it avoids mistakes by being careful.
Instead of that, we’ll only give the handler a narrow object that can only do specific things.
The handler gets a “capability” object that’s already been authorized (if auth fails an error is returned before the handler is called) and only exposes the operations this route is allowed to perform.
What this essentially does is make sure that we can’t leak data from other tables by accident, because by construction, it just doesn’t have access to any methods that fetch irrelevant data.
In a production project I’d probably make these even more granular — e.g. BoundProjectUpdateDetailsCapability,
BoundProjectArchiveCapability.
How this can help us
This is a standard design pattern, right?
It’s just dependency injection during construction.
But it turns out that if it’s applied systematically, this is all we really need to get all these benefits we talked about earlier:
Smaller agent context
If a handler has full DB access, it’s a lot of context to load the “relevant actions”.
But if the handler takes BoundProjectWriteCapability, we only need to add the code for that specific capability to the context.
We’d need tooling or skills for this to be effective, but that’s fine.
This is better for saving tokens and for not overwhelming the agent with irrelevant details (which also helps open the door for using smaller, cheaper or local models for some tasks).
Categories of mistakes become impossible
Like with any other “make illegal states unrepresentable” (e.g. static typing) -
It’s easier to avoid a mistake like accessing the wrong data if it’s literally impossible to make it than if you have to be careful to avoid it.
We can have our nice UX
The theoretical UX we talked about is now possible.
We need a static analyzer that can understand which capabilities we give each endpoint, but that’s just a couple of prompts to your favorite agent (it only took one prompt IIRC to have claude code make an analyzer for Python-FastAPI).
Then we just need to wire up some tooling to remember capabilities at each commit and have the actual UI.
Possible concerns
We’ve talked about imagining a dev process that is “better” in that it has extra useful parts.
We’ve also seen how we can use classic engineering to make that better process possible.
But I’m sure some objections are coming to mind, so let’s talk about them.
Doesn’t this just move the problem?
Did we not just move the problem from “handlers can leak data” to “capabilities can leak data”?
Not really.
With the classic approach, in a large application with frequent changes over time, eventually some refactor might let a
handler call the wrong utility method in some rare edge case, and that utility method fetches some data that this
handler shouldn’t see.
Any “if” statement anywhere in the code might be the one that connects two things that shouldn’t be connected.
That’s a lot of careful reasoning and testing, over a lot of code changes.
But the capability layer is very small.
It’s simpler to test, and it changes much less often than the handlers.
So we only need to understand and test:
- “Does this capability really only do what it’s supposed to do?”
- “Does the handler get the correct capability?”
This is a tiny effort compared to “every line of code might cause a data leak and we must test that”.
But it’s more code! It’s another thing to know and complicates things!
Yeah, it’s more code.
But it’s LLMs writing this code, not humans.
Does it complicate things?
I would argue, for the reasons above, that the human cognitive load is actually much lower.
The agent’s “cognitive load” is definitely lower because of the smaller context.
I would agree, however, that these ideas are more important for large code bases.
In toy applications, things are typically fine either way.
What makes this AI-first?
“Ok, sure, cute ideas, but most of this is not really AI-specific. Why are you saying it’s AI-first engineering?”
What’s different today is the ROI.
My suggestion is to use patterns like this systematically, in many parts of the codebase.
And this makes much more sense than it did a few years ago.
First - the value is higher because the bottlenecks have shifted.
Creating code is no longer the most expensive thing, so improving other things can now have a stronger impact on the overall process - reducing the chance of agent mistakes is critical for robust development at scale.
Human attention while understanding and reviewing the code is probably the most expensive part, but things like agent context size are also important.
Second - the cost is lower because tedious work is now cheap.
Creating dashboards, writing basic code analyzers - these would be weeks of work for most teams a few years ago.
Now it’s maybe a day or two to create actual working tools using an agent.
Lastly, and this combines both cost and value - conventions, processes, and technical know-how used to have a very high implicit cost and only sort-of work.
Think of something like “We have these layers of tests, for these reasons, and this is how you write each of them” - we would need someone very experienced to define this in the first place, then train each team member until they have the skill set to do it well.
We would also have to convince each team member that it’s a good idea, and make sure they actually do it, including under time pressure.
Statistically, this just didn’t work.
But now, and this is the main thesis of this post series - we can share these patterns as something like a skill or a skill collection (which is what I think of as framework).
Just decide on a “skill set” and that’s what the code looks like.
Crazy times.
How general is the pattern?
The idea of “limiting functionality by design” is, of course, very standard.
This usually makes agent context smaller, and makes it easier to avoid some category of mistakes.
Both make the agent’s likelihood of success higher and the feedback loop smaller.
It’s often pretty simple and will often just work without extra tooling except something like agent skills.
Stuff like granular types (e.g. ValidatedEmail as a parameter instead of str), and often just separation of
concerns.
The idea of having custom workflows can also be useful in many cases
- Some type of technical change can require a senior dev signoff and maybe specific testing requirements
- Some type of visual change can be “low risk, so you just need to eyeball the result and we have an automatic visual diff tool for that” (I believe this one will be very common)
- Domain-specific concerns are also relevant - “no one touches the billing code without senior dev and group manager signoff”.
A couple of words about managed effects
I don’t think this is built-in to any popular language, but it’s been in the functional programming world forever.
It can be applied in many cases and help both reasoning and safety - “What DB tables can this touch?”, “Which files can this read or write?”, “which queues can this send data to?”, “can this access the internet?”.
The special case of zero side effects (pure functions, and with them - immutability) is also extremely important.
I strongly believe that managing side effects is going to be a critical part of agentic dev.
It has such strong implications for setting guardrails, and this is one of the most important concerns with
agentic dev, so it’s hard for me to imagine a world where in 10 years (probably 5), 99.99% of agent coding doesn’t have this.
Either robust frameworks will be created that can force this on existing languages, or the currently-popular languages will be abandoned.
Side notes
While not directly the topic of this post, we’ve implicitly touched on some interesting ideas worth mentioning:
- Dev tooling is “malleable” - we can look at software in other ways than directly through code (the capabilities table) or decide what the review process looks like (forced approval dialog).
- We can have prioritized, domain-specific review artifacts that are separate from the code diff. We can, and should, review by blast radius and category of change.
- Matching the above two items, we can note that the UX concepts I suggested for viewing and reviewing software do not show any code. Given a framework that supports them, they would allow us to think at a higher level of abstraction than code when it makes sense.
Finishing up
This capabilities example is a nice example of why I think of AI-first engineering not only as “design patterns”, but as “frameworks”.
We want ways to reduce cognitive load for humans and increase success rate of agents - we want to choose what’s important to us and make that easy to manage (understand, review), we want to reduce context size, prevent dangerous mistakes.
These are the objectives.
The code design pattern itself is simple - it’s just an enabling tool.
But without using this pattern systematically, we don’t have the capabilities view, and we don’t have the capabilities review UX.
As always, happy to hear what you think - (twitter / x, linkedin).
Appendix: example code
Here’s the same example in code — PUT /api/projects/{id}, before and after.
The code uses the “repository” pattern — a thin wrapper around the DB.
This is taken from a project management example repo I’m using to flesh out these ideas.
The “before” — handler with the full Repository (DB access), auth checks inline:
@router.put("/{project_id}")
async def update_project(
project_id: str,
update_data: ProjectUpdateCommand,
# Repository == DB access.
repo: Repository = Depends(get_repository), # full read/write access to everything
current_user: User = Depends(get_current_user),
) -> Project:
####################################################
# Auth checks.
if current_user.role not in {UserRole.SUPER_ADMIN, UserRole.ADMIN, UserRole.PROJECT_MANAGER}:
raise HTTPException(403, "Insufficient permissions to update projects")
project = repo.projects.get_by_id(project_id)
if project is None:
raise HTTPException(404, "Project not found")
if current_user.role != UserRole.SUPER_ADMIN and project.organization_id != current_user.organization_id:
raise HTTPException(403, "Access denied: project belongs to different organization")
####################################################
# Main logic. Note that it has full access to the entire DB,
# so any mistake here could leak data from unrelated tables.
return super_complex_logic(repo, project_id, update_data)
The “after” — handler depends on a narrow capability; auth runs at construction time:
@router.put("/{project_id}", response_model=Project)
async def update_project(
update_data: ProjectUpdateCommand,
# Write capability, scoped to this project, only constructed if auth checks pass.
# The auth checks run when the capability is constructed.
# The capability's interface only exposes the relevant actions.
capability: BoundProjectWriteCapability = Depends(get_bound_project_write_capability),
) -> Project:
# Main logic. It only has access to write operations on this specific project.
return super_complex_logic(capability, update_data)
# ... elsewhere ..
# The capability will look like this:
class BoundProjectWriteCapability:
"""Project write operations scoped to a specific, already-authorized project."""
def update(self, command: ProjectUpdateCommand) -> Project:
...
# def delete...
# def archive...
# def unarchive ...
# No other methods are exposed.
You can have a look at the repo to see how this connects to the rest of the codebase (at least at the moment of writing I only implemented this pattern for the project update endpoint, but if you’re reading this in a few days, I’ll probably have Claude finish it).