
Here it is in PyCon US 2023
Sometimes, in a test, we switch a part of the system, a dependency, with an alternative implementation.
These are called test doubles. Things like stubs, mocks and fakes.
A few of the central reasons for doing this are:
- Performance - if the real thing is too slow to run a lot of tests, we switch it with a fast test double.
- Control - it might be difficult or impossible to set up the real thing in a certain state or make it behave in a certain way. Maybe it’s non-deterministic, maybe it has side effects that are not acceptable in tests. But tests doubles are under our full control and won’t create side effects we don’t want.
The problem with test doubles
Test doubles can be useful, but they are a re-implementation.
They know the implementation details of the thing they’re replacing.
Different types of test doubles do it differently, but this is what they do.
The main problem this causes is correctness.
The test double might not behave exactly like the real thing, and that makes the tests less accurate, less correct.
And as time goes by, the real thing might be slowly changed, but the test double would stay the same.
So it would drift further and further from reality.

And, of course, this can hurt your foot.
This is actually a flavor of the implementation vs. behavior problem.
There are some differences, but essentially, it’s the same category of issues - tests that use test doubles are not as good at catching bugs, and sometimes they fail even though the code is correct, causing all that extra work.
But the problem is that they’re necessary - the problems they solve are real.
What can we do?
The question is - how do we use test doubles and avoid the pitfalls?
I’ll suggest a couple of ideas.
Code design
Code design is so important.
Try to design so you can test a lot of functionality effectively, with fast unit tests, that don’t need test doubles.
If that’s not possible, design so you can choose test doubles with good ROI (see below).
I would argue that this is one of the most important considerations in code design.
Not ALWAYS possible, but a lot of times it is.
What type of test double?
Another thing is to choose which type of test double you’re working with.
And I suggest to mostly use fakes.
A fake behaves like your dependency, but fast.
It’s essentially a simulator for a specific aspect of your dependency.
For example, a fake database table can be an in-memory list of tuples, where each tuple is a row.
In tests - it behaves the same way.
One of the nice things about fakes is that they can be made more reliable.
Test the fake itself
We can make a fake more reliable by writing some tests, not for the code - but for the fake itself.
For example, we can run the same operations against the fake and the real thing and verify we get the same results.
It’ll never be 100% the same - we make tradeoffs in how much we are willing to invest in testing the fake.
Maybe there’s already a good fake?
Sometimes, a reliable fake already exists.
For example, if you’re using SQLite - an in-memory option is built-in.
SQLite can actually be used as a fake for many other SQL databases (though you would need adapters to handle some differences, of course).
So google it, maybe you’ll get lucky.
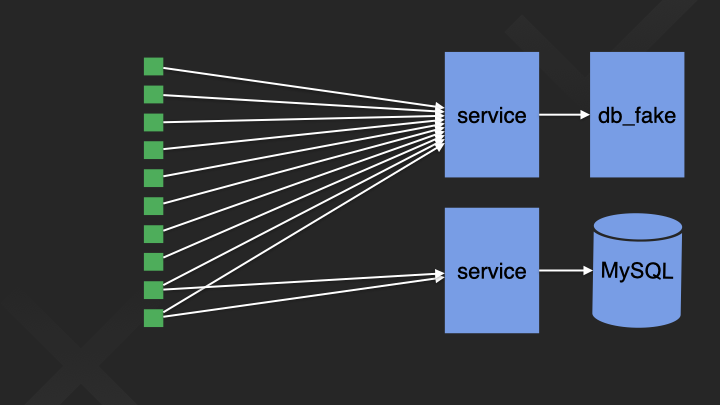
Run the same test with the fake and the real thing
An interesting thing you can do with fakes, is to run exactly the same test - once with a fake, and once with the real thing.
For example, maybe we have 10 tests, and that’s too much to run against the real thing.
So we run all 10 with the fake.
And then, we choose the 2 most important ones, and we run them ALSO with the real thing - maybe every time, maybe just in the nightly.
And this gives us some real world certainty.
Conclusion
The essence here is to use test doubles, while investing some effort to verify their reliability, until we get an acceptable tradeoff.